The main objective of machine learning is to extract patterns to turn data into knowledge. Since the beginning of this century, technological advances have drastically changed the size of data sets as well as the speed with which these data must be analyzed. Modern data sets may have a huge number of instances, a very large number of features, or both. In most applications, data sets are compiled by combining data from different sources and databases (containing both structured and unstructured data) where each source of information has its strengths and weaknesses.
Before applying any machine learning algorithm, it is therefore necessary to transform these raw data sources into meaningful features to help the machine learning models achieve better performance in terms of either predictive performance, interpretability or both. This essential step, which is often denoted feature engineering, is of utmost importance to improve the performance of machine learning models. This is confirmed by Kaggle master Luca Massaron: “The features you use influence more than everything else the result. No algorithm alone, to my knowledge, can supplement the information gain given by correct feature engineering.
Research examples
- Feature selection and dimension reduction: Recent developments for high-dimensional data have focused on dimension reduction (e.g. principal component analysis) and regularization methods that impose sparsity so that the model remains estimable and an automatic feature selection is obtained. Such parsimonious models reflect the main structure in the data and increase the interpretability of the model. Moreover, by filtering away the noise in the data, more stable models are obtained which are much more trustworthy when generating predictions for new cases.
- Anomaly detection: Modern data sets are collected at high speed from different sources and typically contain some anomalies or outliers. These may be caused by errors, but they could also have been recorded under exceptional circumstances, or belong to another population. Anomalies may spoil the resulting analysis but they may also be the most interesting cases in the data and therefore it is important to apply advanced anomaly detection techniques.
- Transformation and creation of features: The existing features may be very nonnormal and asymmetric which often complicates the next steps of the machine learning process. The Box-Cox and Yeo-Johnson transformations are popular tools to transform these features. Other features might require transformations because they are too granular to be meaningful. In marketing, credit scoring and fraud analytics, the construction of RFM (recency, frequency and monetary) features from transactional data have been very useful. Another important set of features are trend features, which summarize the historical evolution of a variable in various ways.
-
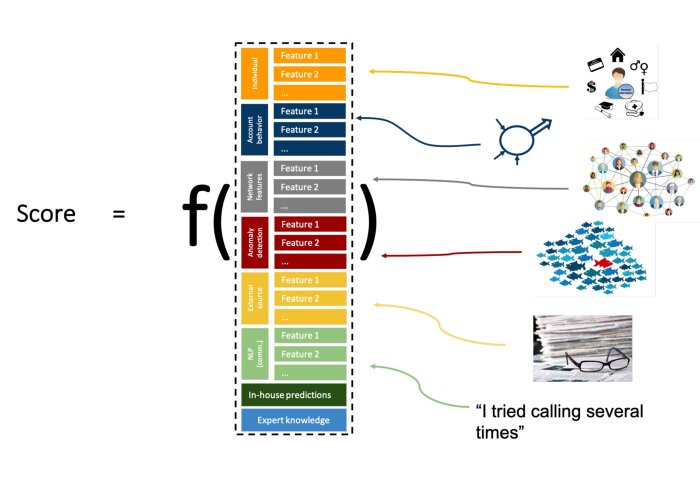 IDLab studies and implements feature engineering techniques for improving data science applications such as fraud detection, insurance analytics, credit risk analytics, churn prediction and cycling performance prediction
IDLab studies and implements feature engineering techniques for improving data science applications such as fraud detection, insurance analytics, credit risk analytics, churn prediction and cycling performance prediction

Involved faculty

